Apache Kafka is the foundational architecture most developers choose when building streaming applications. It’s incredibly scalable, fault-tolerant, and dependable. And its popularity has yielded vast knowledge with an active community to support developers when they build applications. Naturally, Kafka is now a table-stakes data platform component for nearly every major enterprise that deals with events data.
Tinybird’s Kafka connector was the first native data connector for a third-party system that we built. It's how many developers get data into Tinybird, and we've grown to support ingestion from hundreds of concurrent topics. But with that growth, we also realized we had a problem.
We originally designed our Kafka consumers to optimize for two factors: throughput and availability. This system worked quite well to solve these two factors, but we quickly discovered a scalability issue.
In a nutshell, we realized we were headed for exponentially increasing Kafka costs with only linear customer growth. Not good for a serverless platform that’s billed based on usage. With the growth we’ve experienced since our GA launch, we knew we needed to quickly change course so that our Kafka consumers could handle the scale.
In this post, I’ll explain how we used rendezvous hashing to reimagine and revamp our Kafka infrastructure so we could ingest events from hundreds of concurrent Kafka topics. This new approach significantly reduced our Kafka connections - and associated costs - while continuing to support the throughput and availability goals of our original architecture.
You can read on to learn how Tinybird addressed horizontal scalability with Kafka. You can also start developing with Tinybird for free today. If you’re trying to build analytics on Kafka data, you’ll likely find Tinybird useful, so feel free to give it a try.
The context: How does Tinybird work with Kafka?
Tinybird is a platform for developers to build low-latency APIs really quickly on top of streaming data, and many companies (like Vercel, Situm, and The Hotels Network among others) use Kafka to ingest event data into Tinybird.
The native Kafka connector included with Tinybird lets you connect to a Kafka cluster, whether that’s a self-hosted Apache Kafka instance or any one of the hosted/self-hosted variants out there (Confluent, Redpanda, Upstash, etc.).
Tinybird provisions agents (consumers) to consume topics from client clusters and writes that data into ClickHouse. From there, you can write SQL queries to enrich and transform the data, and publish the results as low-latency REST APIs.
The problem: Too many Kafka connections
Kafka is perfectly designed to scale with partitions. If you have more load on a single topic, you can just increase partitions and consumers accordingly, and everything scales. Auto-scaling Kafka to handle traffic spikes from high-rate topics using something like Kubernetes is pretty trendy right now, and the process has been well documented by some (here, here, and here. There are many more such blogs).
In our case, however, the problem wasn’t necessarily a single topic with very high traffic, but rather hundreds of topics with more moderate traffic. It’s a completely different class of problem, and adding partitions wouldn't solve anything for us.
To better understand why that was troublesome, take a look at this simplified diagram of the architecture we first built.
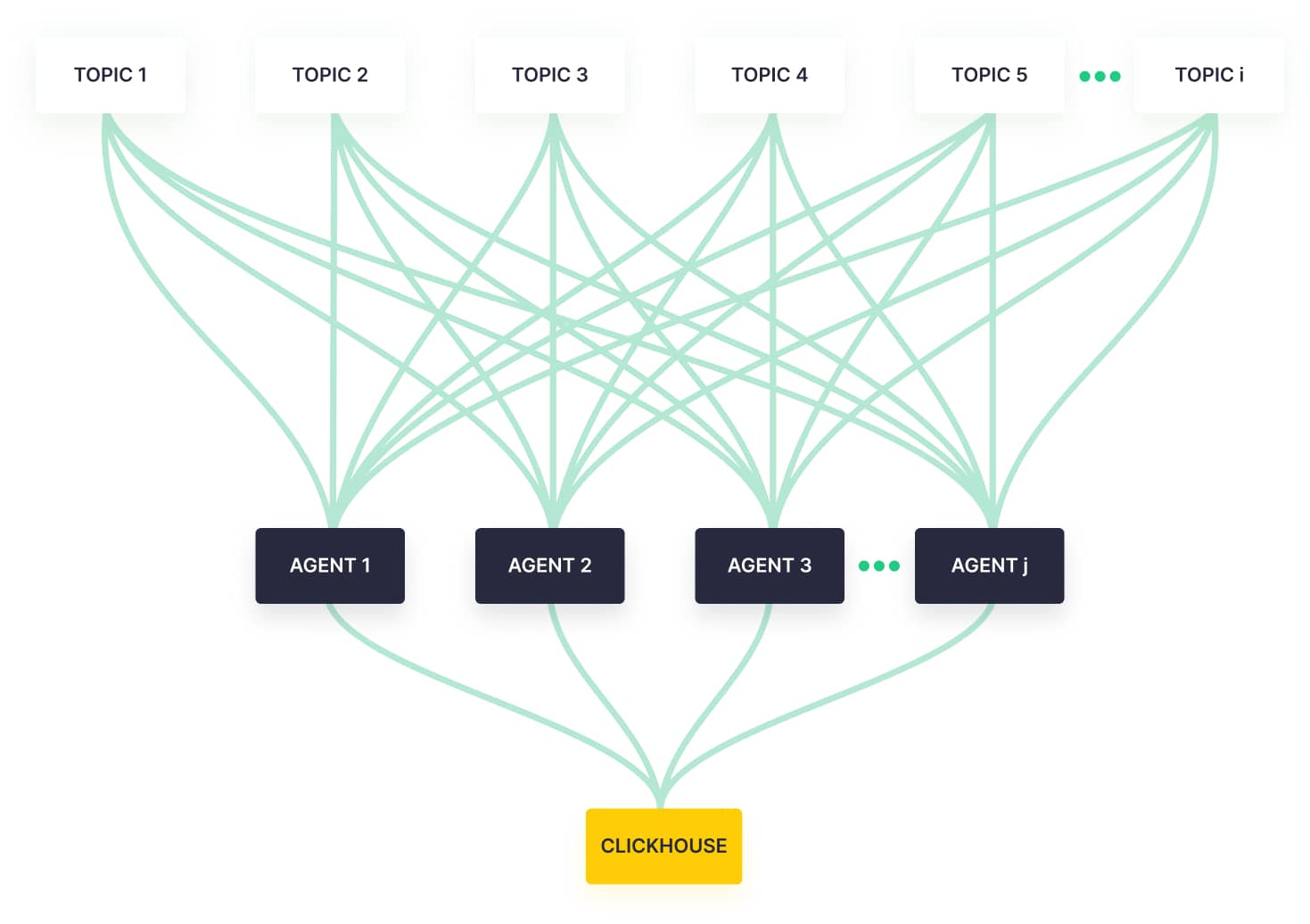
You can see that every Kafka agent (a Tinybird Kafka consumer that processes data for multiple topics) was connected to every single topic.
Even though Kafka allows you to connect more consumers to a topic than there are partitions, those extra consumers will ultimately be assigned to zero partitions for some topics. In an ideal world, you don’t want to maintain connections from consumers to topics for which they have no partition assignment.
Our problem was that we maintained too many Kafka connections: one for each topic-agent combination.
Despite this, we still maintained connections, idle or not, to every topic from every agent.
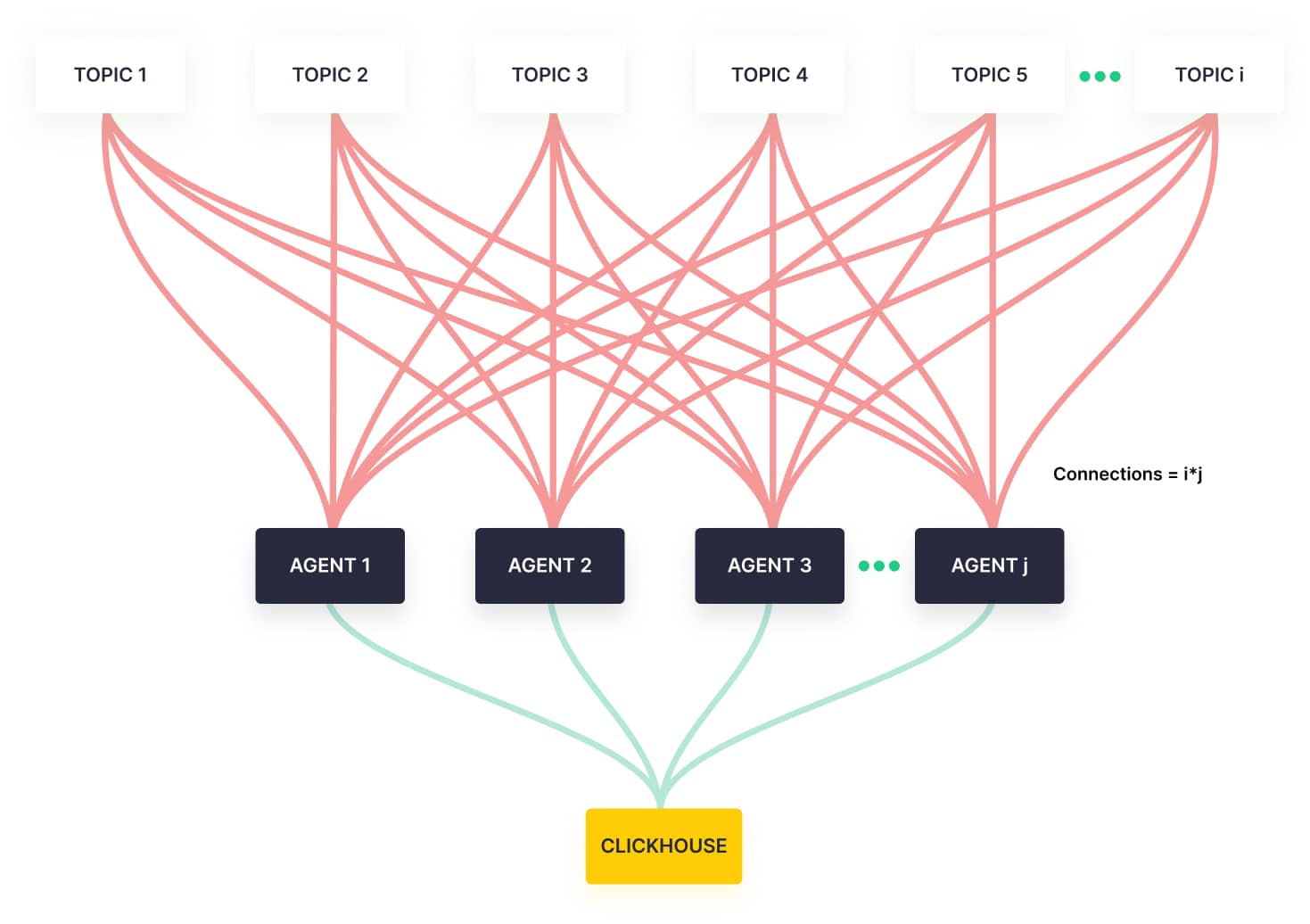
You can see why this didn’t scale well.
As we added new users or existing users scaled up, we could of course add more agents to handle the additional throughput. But with each new user or use case, we also added more topics. And every agent we provisioned would connect to each new topic on top of their existing connections.
That’s a lot of connections.
So, instead of a nice linear scale, we had something closer to a quadratic curve. If usage doubled, we'd more than double our infrastructure, which more than doubled our cloud bill. It was the opposite of “economies of scale”.
What we needed: Reduced connections without compromise
Like many others, we set up our Kafka implementation to consume a single topic on a single thread. The fundamental issue with our approach, then, was that every Kafka agent unnecessarily opened a connection to every single topic.
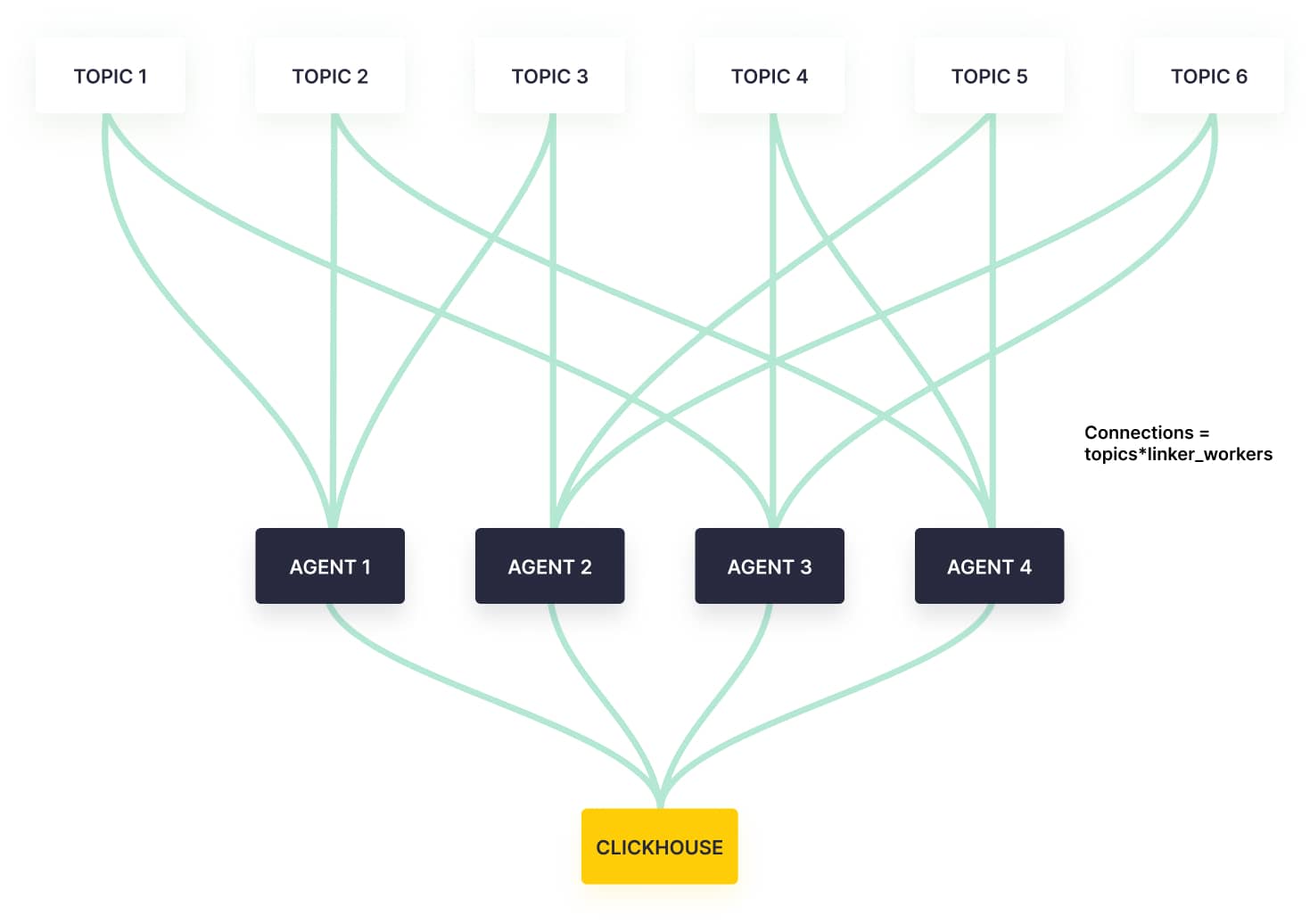
To avoid creating more threads than needed, we wanted to partition our agents so that each agent wasn’t responsible for every topic. This would reduce the number of connections we needed, making our infrastructure more manageable and cost-efficient.
We wanted to be able to partition our Kafka consumer agents to minimize Kafka connections while maintaining some of the desirable properties of our initial approach.
But, the system we had in place did have some desirable properties:
- High Throughput. Because we had a connection from every agent to every topic, we could consume data from topics with as much parallelism as possible. We could scale down and have a single consumer per partition, or we could scale up to as many agents as we had provisioned.
- High Availability. If one agent suffered a problem, the rest could easily handle the added load automatically. Since each agent was connected to every topic, Kafka's rebalancing mechanism would kick in when needed.
We knew that we’d want to carry these properties over into our new design.
Our solution: Rendezvous hashing
We started by adding a new configuration parameter to the ingestion of each topic. We call this parameter linker_workers, and it's purpose is to limit the number of agents that can connect to any of our client’s Kafka clusters.
For example, if we’ve provisioned N agents, we theoretically have N potential agents that could work on a cluster, but we only want to allow linker_workers agents to actually work on it.
With linker_workers in hand, we needed an algorithm that would assign agents to topics as a function of this new parameter.
A naive solution wouldn’t work well. The selection needed to be shared by all agents and made in a random(ish) manner to ensure the load was distributed uniformly across all agents. As an added wrinkle of complexity, we wanted to be able to add and remove topics and agents without having to rebalance everything.
With this in mind, we selected rendezvous hashing, also called “highest random weight” (HRW) hashing. Rendezvous hashing evenly distributes keys across a cluster of servers while minimizing the amount of remapping when servers are added or removed from the cluster. We found it to be the perfect hashing algorithm for this use case.
We chose rendezvous hashing to intelligently distribute agents across hundreds of topics with a very lightweight implementation.
How we implemented rendezous hashing
This is how we implemented rendezvous hashing to horizontally scale our Kafka agents:
1. Each agent generates a unique agent ID (a UUID).
2. Each agent announces that it's alive with the current timestamp via Redis.
3. Each agent gets the list of alive agents and their IDs and the list of all topics and their unique IDs (we don’t use topic names as they may not be unique across multiple clusters).

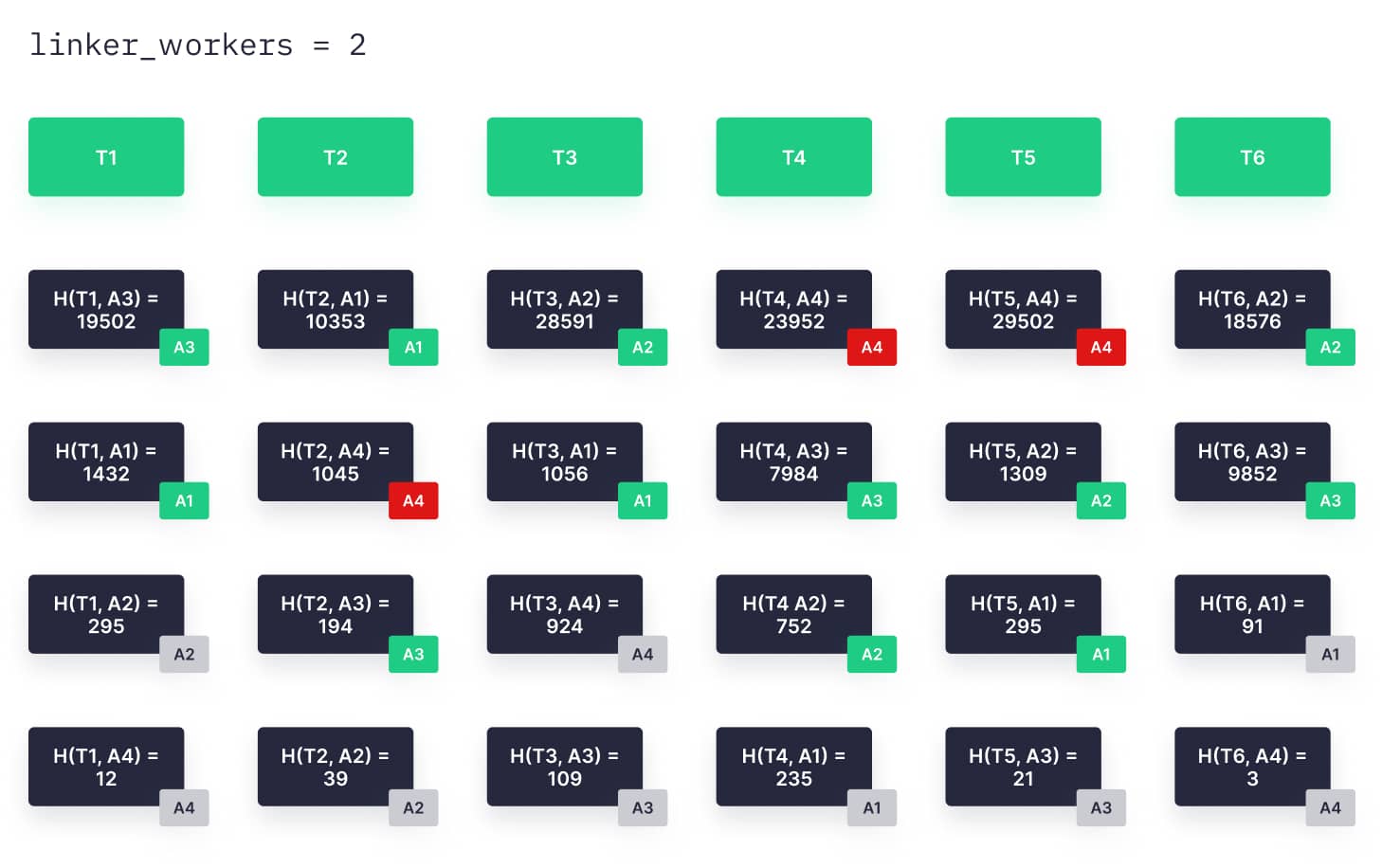
4. Each agent computes an integer hash from the concatenation of the agent ID and topic ID for each agent and topic (for a total of agents*topics hashes).

5. Each agent generates a sorted list of hashes for each topic.

6. For each topic-specific list, if the index of the hash associated with an agent is less than linker_workers, then that agent is responsible for the topic.

7. Each agent runs this process in the background, stopping and starting ingestion from topics as the algorithm chooses.
8. In the event that an agent fails, topics previously consumed by that agent will fail over to the next agent in the sorted list of hashes.
This results in a number of desirable outcomes:
- We reduce our Kafka connections. And in turn, we reduce our costs to maintain them.
- The solution is very lightweight. Writing and reading a few UUIDs and timestamps from Redis is cheap.
- We achieve uniform load distribution. If the hash function is sufficiently random, the topics will be spread evenly across all agents.
- We avoid continuous rebalancing. When the list of topics and agents remains constant, the assignment remains constant.
- Rebalancing is minimal even when new topics or agents are added.
- We retain control over the number of agents for each topic, since we can manually increase
linker_workerson a single topic for transient traffic spikes (e.g. Black Friday for retailers). - We maintain high availability. Agents may fail, but the lack of keep alives will automatically trigger the rebalancing system, and other agents will work as an implicit failover.
Rendezvous hashing allowed us to randomly and uniformly assign fewer Kafka agents to each Kafka topic, and minimized rebalancing when topics or agents were added or removed.
Why rendezvous hashing?
Now, maybe you’re wondering why we went this route. If you’re a savvy Kafka developer, you probably wondered why we didn’t explore consuming multiple topics from a single thread to reduce our number of connections.
The short answer is that we could have, but there are a few reasons we didn't, some technical, some operational.
For one, having a single thread per topic just makes things easier for us to work with, and it isolates different clients and topics to avoid friction that might occur between them.
We could have made some changes at the librdkafka level (see this), but we didn’t really want to pursue this (at least not yet).
Rendezvous hashing was the right choice for us and at this time. We'll continue to explore ways to auto-scale our Kafka infrastructure as efficiently as possible.
With where we were as an engineering team, the isolation and simplicity were desirable, and refactoring to group multiple topics on a single consumer would have been very time-consuming. And even then, we weren’t sure that refactoring alone would have improved performance as much as the solution I've described here, especially without optimizing the Kafka consumer itself.
So we chose to add a second layer with rendezvous hashing to create consumers only when needed.
This choice prioritized speed and simplicity in development while maintaining our throughput and availability priorities in the product, and it succeeded in achieving those priorities.
What’s next?
In this post, I've explained how we scaled Kafka horizontally to consume from a large number of concurrent topics. This has created a solid foundation for managing our infrastructure. Of course, as usage grows, we will have to continue thinking about how to scale infrastructure (ideally automatically) and how to ensure that the software manages to use the new hardware without significant drops in efficiency.
We plan to continue exploring options for auto-scaling our Kafka agents in 2023, and as we build, we’ll be sure to write about it.
Conclusion
Usually, when you think of scaling Kafka, you think about scaling throughput in a single topic. But creating an efficient system that consumes data from many different Kafka topics can prove to be a challenging problem.
We were determined to find a lightweight solution, and we did so with rendezvous hashing. Now we can scale new topics and new agents without the outsize increase in infrastructure costs.
--
If Tinybird sounds interesting to you, I’d encourage you to try it out. The free plan is generous, and support for Kafka ingestion is top notch 🙂. There are some nice benefits to using Tinybird versus a naive solution that just writes Kafka data to a real-time analytics database. For example:
- Tinybird controls errors and provides quarantine tables to avoid blocking ingestion, while still letting you know if there are any issues.
- Tinybird supports JSON, AVRO format, and Schema Registry integration for automatic deserialization.
- Tinybird offers built-in ingestion observability with in-app visualizations and service data tables that you can query and publish endpoints over.
- As a serverless solution, Tinybird handles the scale for you, so you don't have to worry about provisioning machines.
...and if you don't use Kafka, you can try our streaming HTTP endpoint 😎.
If you want to go deeper into Tinybird, check out the docs, and if you get stuck, come join our Slack.











