Snowflake is a powerful, scalable, secure, and cost-efficient data warehouse used by thousands of companies to store structured and semi-structured data, run analytical workloads and aggregations on that data, and build business intelligence dashboards to make faster, more accurate strategic decisions.
That said, Snowflake doesn’t solve every business use case. In particular, and as with other cloud data warehouses, Snowflake is not optimized to support real-time data analytics projects. It can’t always provide the latency and request concurrency required by typical user-facing applications.
Snowflake is not optimized to support real-time data analytics.
As a result, while it is a fantastic data warehouse, Snowflake isn’t usually the right choice for underpinning real-time applications at scale. In addition, many techniques developers employ to overcome Snowflake’s latency and concurrency issues come at a considerable cost.
Tinybird’s first-party Snowflake Connector is designed to make it simple to build real-time applications on top of Snowflake data. The Tinybird Snowflake Connector provides intuitive UI and CLI workflows for near-real-time data ingestion from Snowflake into Tinybird so that you can publish low-latency, high-concurrency, SQL-based APIs that empower your organization to build revenue-generating real-time analytics use cases.
But speed isn’t the only variable here. The Tinybird Snowflake Connector makes it possible to build a low-latency publication layer on top of Snowflake at roughly a tenth of the cost of alternative techniques. More on that below.
Tinybird’s Snowflake Connector makes it possible to build a low-latency API layer on top of Snowflake at roughly 1/10th the cost of using Snowflake alone.
Read on to learn more about the Tinybird Snowflake Connector, how it is built, and how to use it to build low-latency, real-time data pipelines and use cases over Snowflake tables.
You can also check out the documentation for more implementation details. If you’re new to Tinybird, you can sign up for free (no credit card needed) and start syncing data from Snowflake and many other sources today. Also, feel free to join the Tinybird Community on Slack to ask any questions you may have.
What is Snowflake?
Snowflake is a powerful cloud data warehouse. Like other cloud data warehouses such as BigQuery, Redshift, and Azure Synapse Analytics, Snowflake offers the benefits of separated storage and compute, serverless data management, and an SQL interface for building and running analytical queries.
Unlike its single-cloud counterparts, Snowflake can be run on any cloud platform (AWS, GCP, Azure), giving it a flexible architectural advantage.
Data engineers use Snowflake as a part of their larger data ecosystem to build batch analytical queries to power business intelligence applications.
Does Snowflake support real-time?
While Snowflake has made strides in minimizing ingest latency for streaming data through tools like its Kafka Connector and Snowpipe, it still doesn’t work well for most real-time applications.
Real-time applications require a data publication layer (API) to handle many concurrent requests with minimal latency. This API must also incorporate the freshest possible data to be useful for real-time use cases.
Snowflake struggles to handle real-time use cases due to its query pool and limited query concurrency per warehouse.
Why is Snowflake slow?
Snowflake is slow in real-time use cases for two main reasons: 1) it handles queries in a job pool, introducing non-deterministic latency, and 2) query concurrency is limited per warehouse.
- Handling queries in a job pool. Like many data warehouses, Snowflake processes query jobs in a pool shared by many end users.
While queries can be highly optimized within Snowflake to return results in seconds or less, the execution might be delayed. The job pool introduces overhead on queries, so even the simplest query likeSELECT 1, which requires effectively zero compute resource, may take a second or two to respond depending on compute availability.
The only way to overcome this hurdle is to increase the job pool limit, a task that is largely manual and difficult to automate.
Furthermore, increasing the job pool limit only offers superficial improvements. In reality, to scale query concurrency on Snowflake, you’ll have to spin up new virtual warehouses or increase their cluster limit.
These limits may not be problematic for batch processing workflows that support business intelligence or offline data science and machine learning workloads, but they become a serious bottleneck when creating real-time data apps. - Limited query concurrency per warehouse. When developers want to build real-time applications with data in Snowflake, they might try to build a web service on top of Snowflake to query the data through HTTP requests from their applications.
This approach is limited by the concurrency constraints described above and further requires additional instances to scale. You’ll need to provision many virtual warehouses to make it work, and at considerable cost. Because of this, scalability becomes a big concern when you need to support a highly-concurrent set of users that want access to data in Snowflake.
Recently, some developers have tried building “cache” layers on top of Snowflake, for example, by moving aggregated metrics to Redis or Cloud SQL. They’ll then build their web service on top of that. While this drastically improves performance by moving the data to the cache, the data itself is not fresh. It still depends on ETL processes running from within Snowflake using tools like dbt and Airflow.
Tinybird: A real-time data platform that works with Snowflake
Tinybird is a real-time data integration for your Snowflake data, empowering rapid development of real-time data products while eliminating the challenges described in the prior section.
When it comes to building real-time systems with Snowflake datasets, Tinybird reduces costs in 2 key ways:
- Faster development speed and shorter release cycles. Tinybird is a ready-made real-time publication layer for Snowflake. Developers can focus their efforts on application development, since Tinybird allows you to design data views using standard SQL and instantly publish them as HTTP endpoints.
Instead of spinning up a web service or cache layer, developers can use the Tinybird Snowflake Connector to quickly build APIs for their applications that meet their latency and concurrency requirements. - Reduced compute cost. Building a publication layer on top of Snowflake using traditional methods will require that you instantiate additional virtual warehouses to handle the added compute load.
There’s an upfront cost to a new virtual warehouse in Snowflake: You’ll have to appropriately size the warehouse, and allocate resources to it. The cost of that warehouse will depend on how long you use it (hourly).
Tinybird simplifies and reduces costs by only charging for data processed through published APIs. Instead of being billed for every query and the amount of time you use a pre-provisioned, pre-sized warehouse, you’ll only be billed for the amount of data processed by your Tinybird APIs.
Tinybird significantly reduces both development cost and compute cost when building and running real-time APIs on top of Snowflake data.
A real-time example with Snowflake
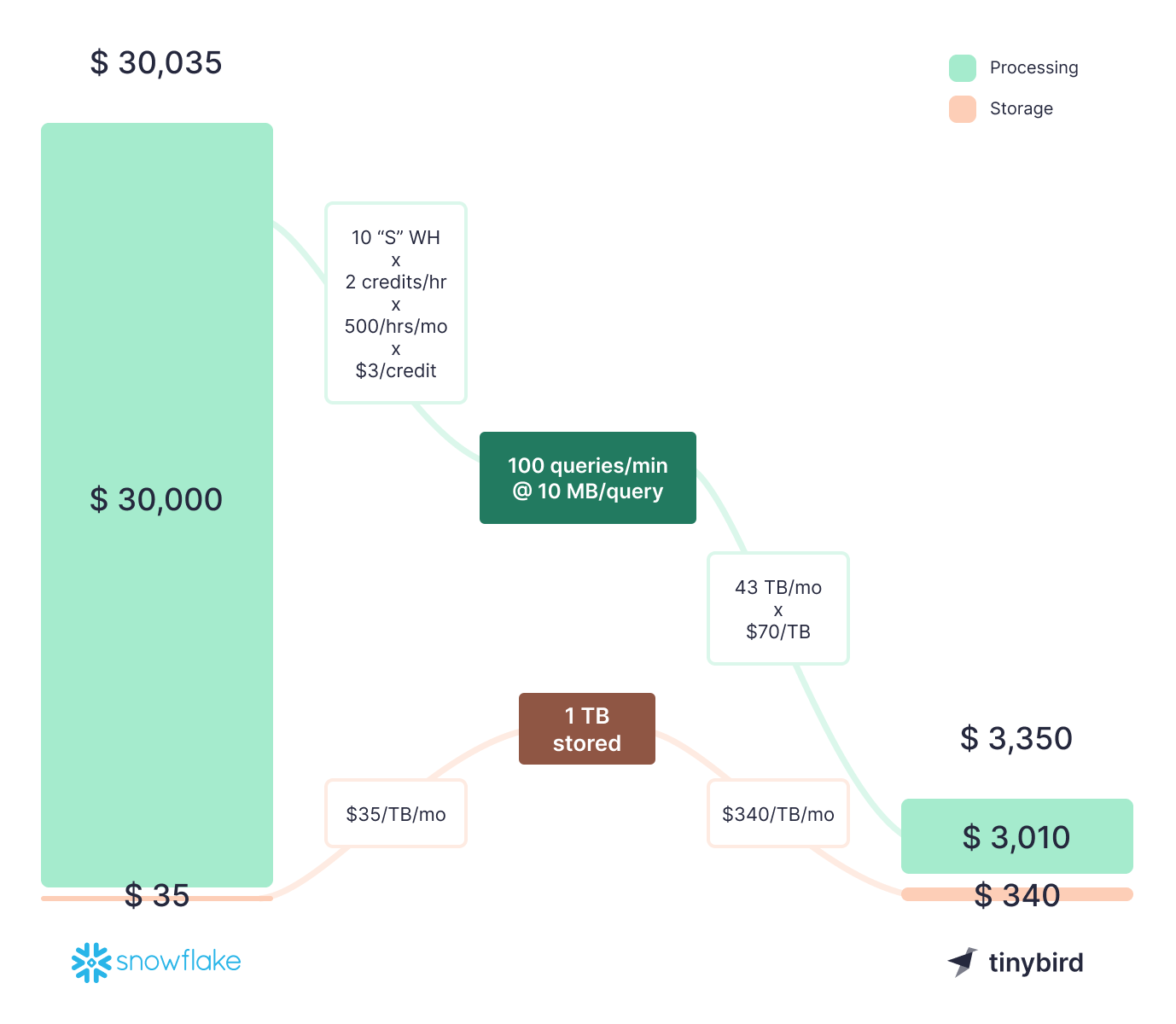
Let’s dig into this a bit more with a realistic example. Suppose you want to build an application that queries data in Snowflake. You have about 1 TB of data in that table, and you expect that you’ll need to serve roughly 100 queries per minute via the APIs that your application uses to interface with your Snowflake data. The average query processes 10 MB of data.
So that’s:
- 1 TB of data storage
- 100 queries/min * 10 MB/query * 1440 min/day * 30 days/month = ~43 TB of data processed per month
A small (“S”) Snowflake Warehouse is likely good enough for this use case, but you’ll need 10 of them to handle the 100 queries per minute since you can only operate on up to 10 clusters per warehouse.
Snowflake will cost ~$30K a month
Based on Snowflake’s pricing (here’s a great explainer), you’ll pay 2 credits per hour per warehouse at ~$3 per credit for 10 warehouses. Assuming those warehouses run 24/7 to support your application, you should expect to pay $1,440 per day for compute in Snowflake.
Of course, you’ll probably find some efficiencies in there, so let’s round down to $1,000/day.
So, to support this use case running queries over Snowflake, you should expect to pay ~$30,000 a month (plus $35 a month to store a terabyte of data).
Tinybird will cost ~$3K a month
Tinybird’s Pro Plan costs $0.34 per GB stored and $0.07 per GB processed by published endpoints. Multiply by a factor of 1K for terabytes, and that equates to $340 per TB stored and $70 per TB processed data.
Given the stats above (1 TB stored, 43 TB processed), you would pay $3,350 per month using Tinybird. As with Snowflake, you’ll likely find some efficiencies through Materialized Views, storage TTLs, and query optimization, so let’s round it down to $3,000 (which is conservative).
Based on this real-time example, if you used Tinybird as your real-time analytics platform to power an application with high user concurrency and low latency on top of Snowflake data, you would pay 10x less than what you'd spend to try to achieve the same in Snowflake. And that's just considering the cost of storage and compute.
In this example, Snowflake would cost ~$30K a month to process 100 queries per minute, whereas Tinybird would only cost ~$3K to process the same workload.
The unsung cost savings
Of course, the example above only considers hard costs to use Snowflake or Tinybird for storage and compute. It doesn’t consider the many efficiencies you’ll gain in your development with a faster time to market using a purpose-built publication layer like Tinybird.
Exploratory queries are always free in Tinybird, so you won't be charged for queries during development.
Additionally, Tinybird never charges you for data processed via exploratory or prototyping queries. Only published API calls and materializations count toward usage of processed data. In Snowflake, you’ll burn credits for every query you run during development even before you ship to production. With Tinybird, that work is free.
How we built the Snowflake Connector
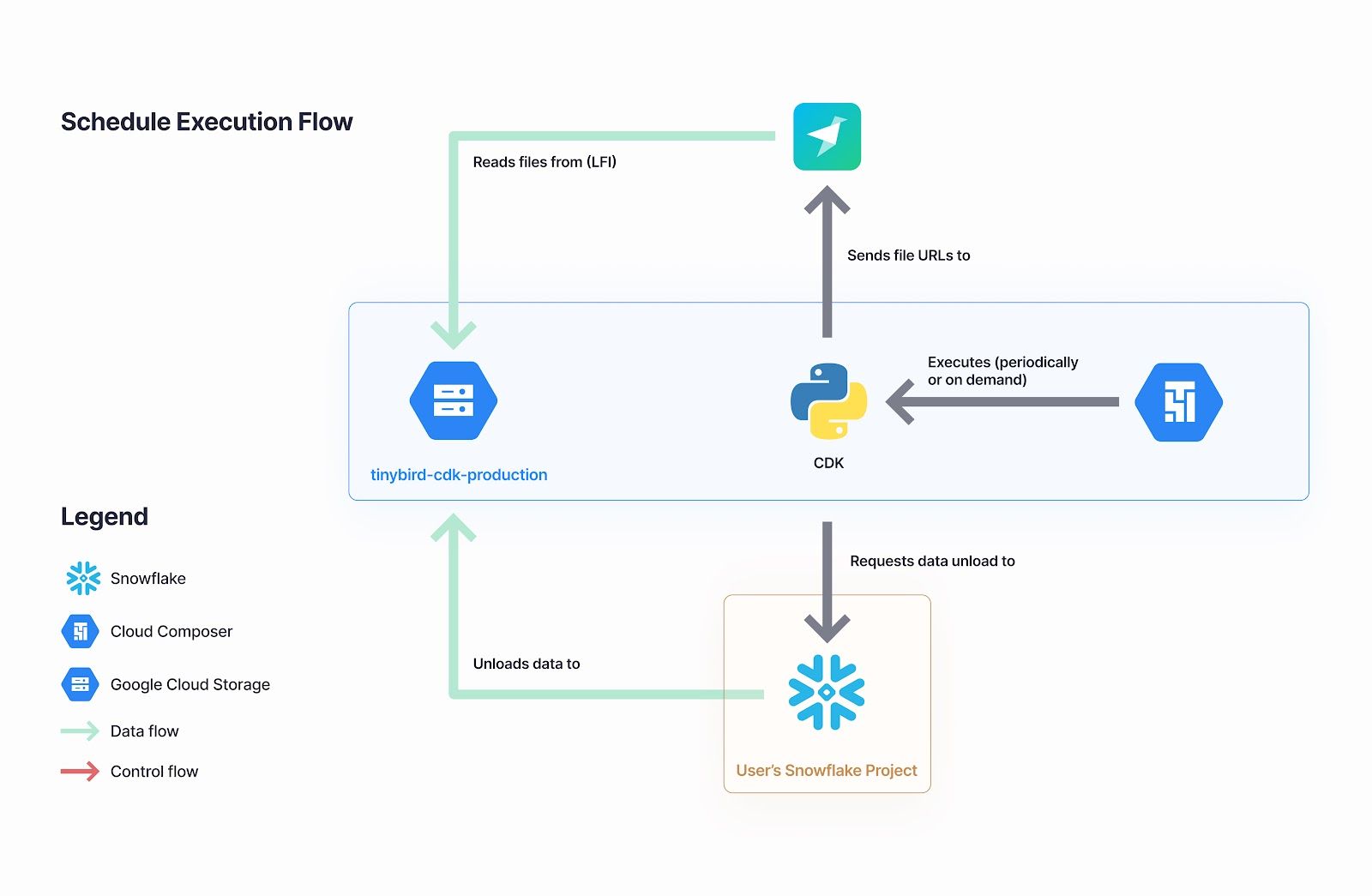
The Snowflake Connector utilizes the Tinybird Connector Development Kit (CDK) which enables our engineers (and in the future, external teams) to quickly spin up managed, serverless connections between their source systems and Tinybird.
The Snowflake Connector follows a near-real-time approach to load data into Tinybird, capturing the latest delta from Snowflake tables and writing them to a Tinybird Data Source. Based on the schedule you set, the Snowflake Connector will run a background job to get results from your Snowflake table based on your import query configuration, then either append or replace data in your synced Tinybird Data Source.
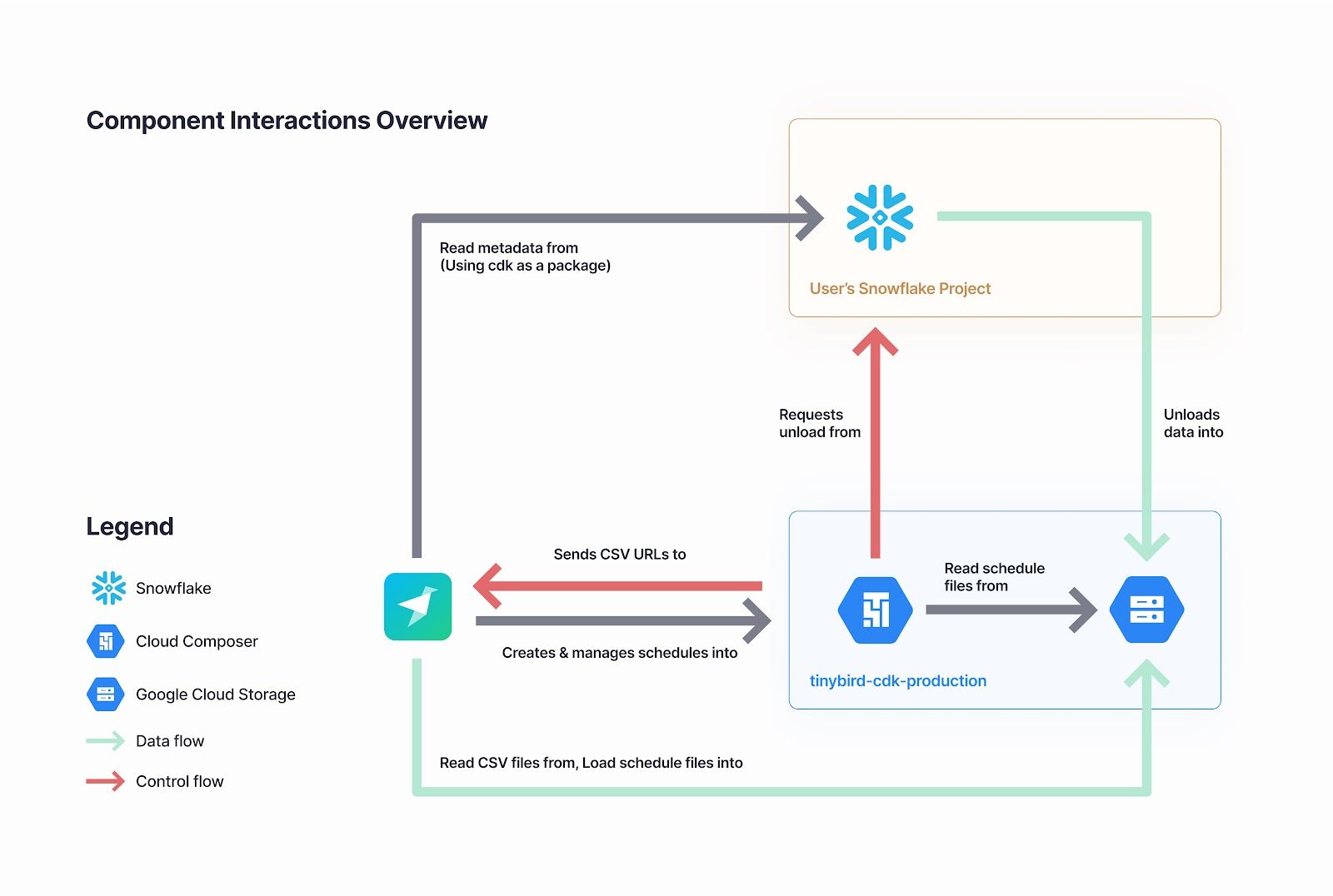
To create a job, you just need to select a table or view in Snowflake and choose how often you want it to sync to Tinybird. That’s it. The background job is automatically created for the user and scheduled in Google Cloud Composer.
The job definition file (following Airflow's DAG specification) includes the Snowflake object reference, Cron expression, the generated extract query, and a Tinybird token as a secret. Google Cloud Composer handles the scheduled job executions in the background, and we’ve utilized the standard Airflow API to allow Tinybird users to trigger a manual sync at the click of a button.
Setting up the Snowflake Connector
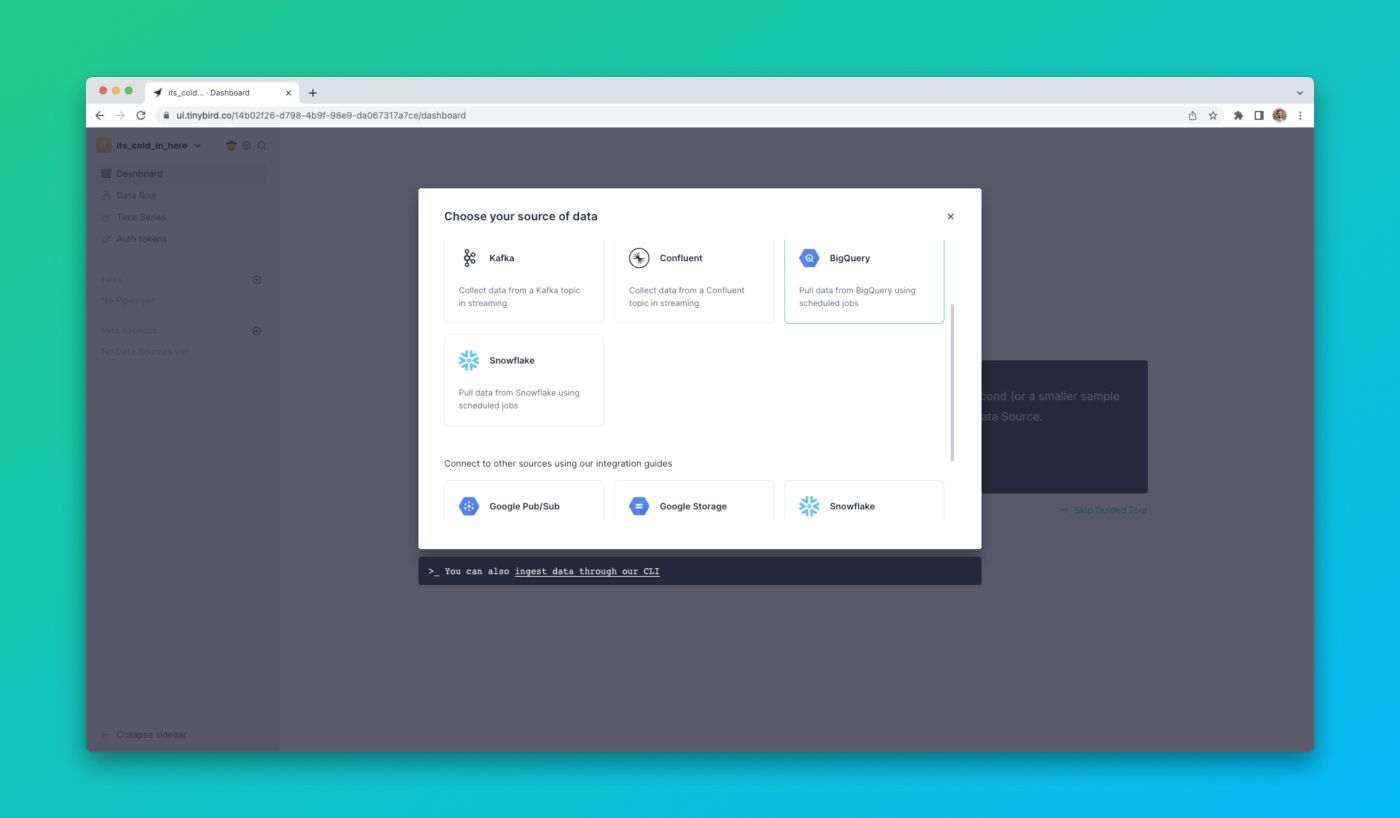
You can set up a connection between Snowflake and Tinybird within the Tinybird UI. Add a new Data Source and select the Snowflake option in the dialog box.
Then you'll authorize Tinybird to access your Snowflake account, and assign Tinybird a role with access to a certain Workspace. When you do that, the UI will dynamically generate an SQL snippet like the one below for you to run in Snowflake. This snippet creates a new integration between Tinybird's GCS bucket and Snowflake, and must be run once for each new Snowflake connection you create.
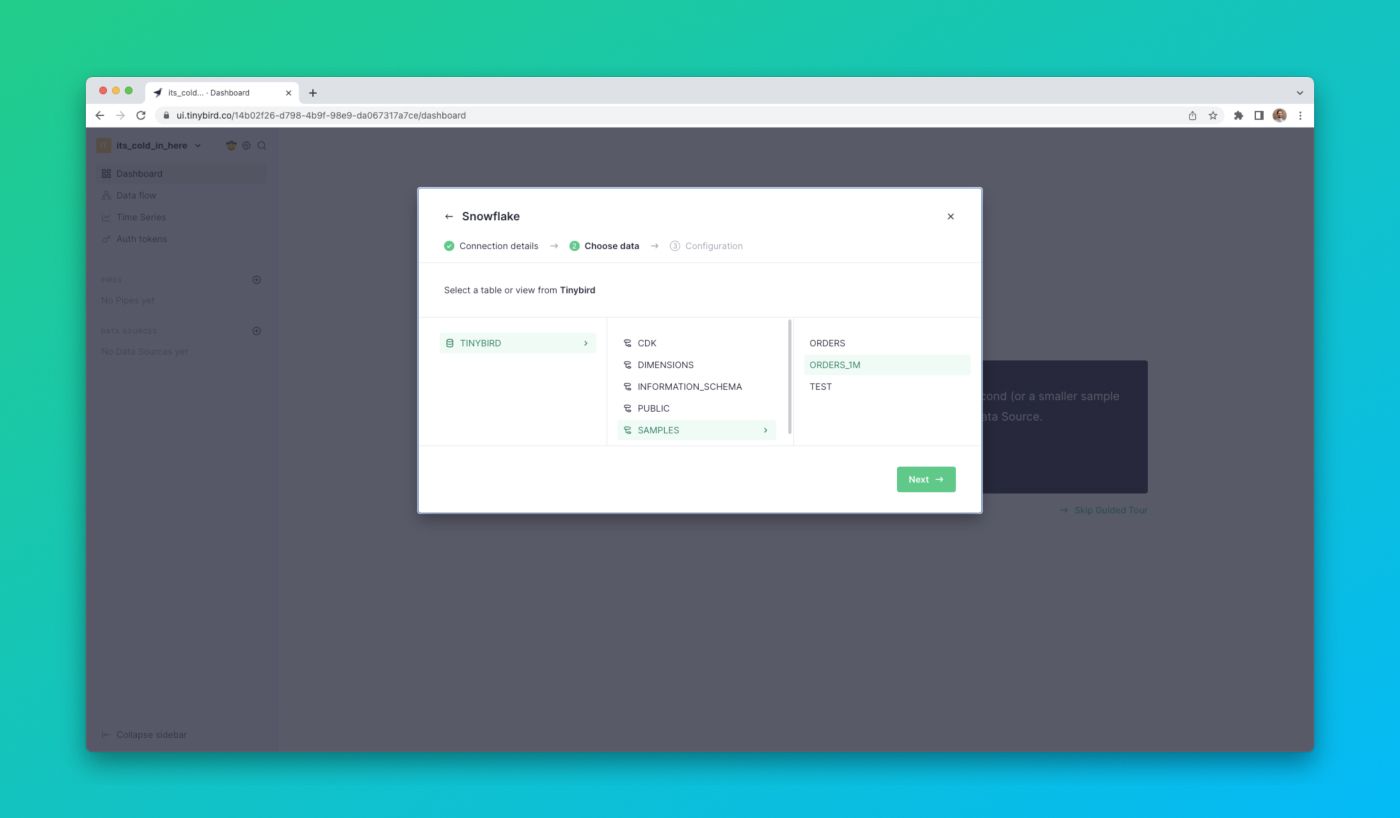
Then, you can select which Snowflake table or view you want to sync to Tinybird, defining the schema of the resulting Data Source that gets created in Tinybird.
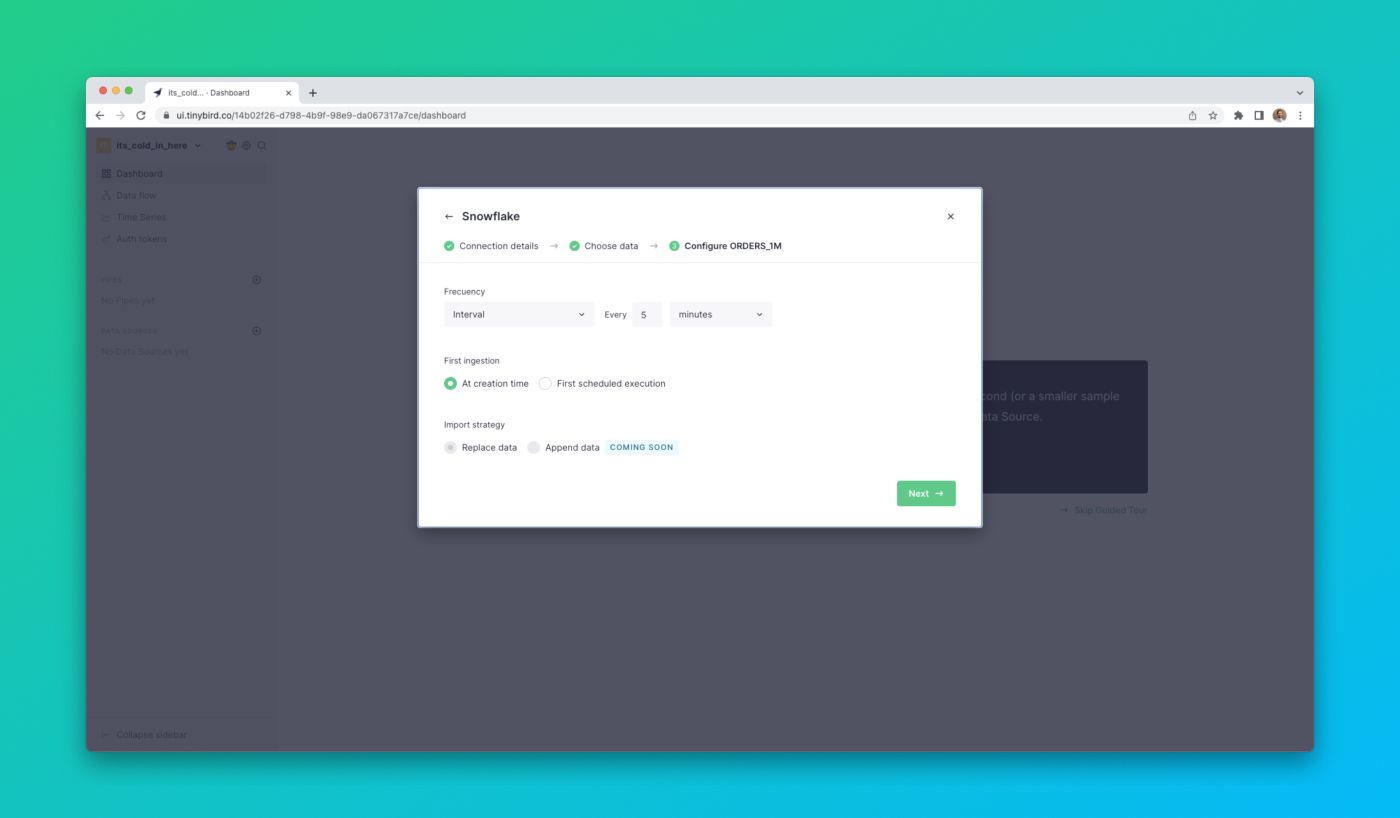
Finally, you can set the sync schedule using an interval or Cron expression, or initiate a one-off ingestion.
Creating real-time data products with Snowflake datasets
With your Snowflake tables synced into Tinybird’s underlying real-time database, you can build SQL Pipes and use your Snowflake data to enrich streams from sources like Apache Kafka, Google Pub/Sub, Amazon Kinesis, or Tinybird’s HTTP streaming Events API.
Then, you can publish your Pipes as low-latency, high-concurrency API endpoints which you can use to build real-time data pipelines and applications.
To see a quick tutorial on how to build fast APIs with Tinybird, check out this 3-minute video:
Monitoring your Snowflake Connection
The Snowflake Connector is a fully serverless connector. You won’t need to set up any infrastructure, and it provides observability, monitoring, and performance metrics out of the box.
To monitor your Snowflake sync jobs, you’ll find a pulse chart in the Data Source detail view in the Tinybird UI. The pulse chart will display the last 50 sync job executions and their success or failure status.

As always, you can check the logs in detail on the same Data Source view.
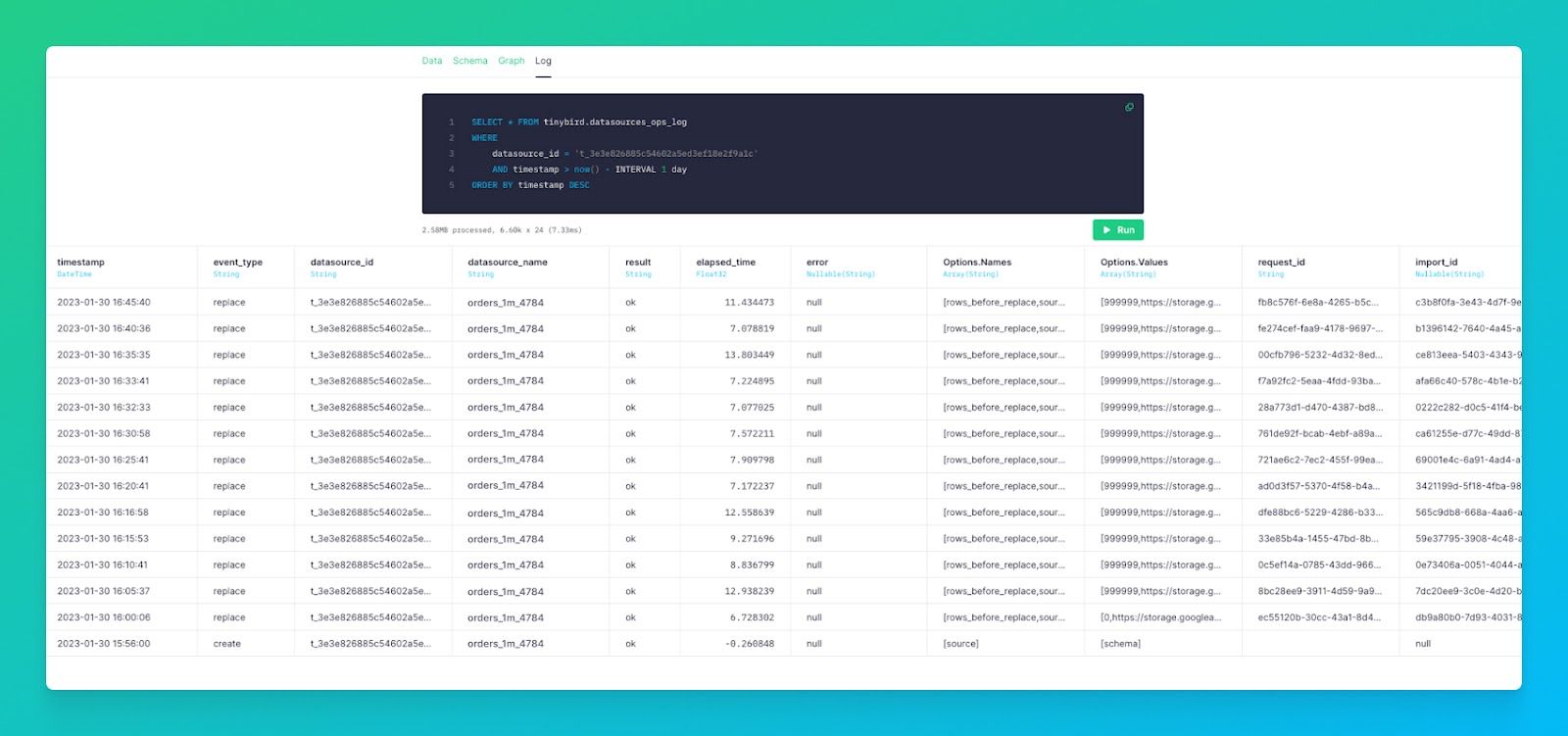
As with any Tinybird Data Source, you can utilize the Tinybird Service Data Source datasource_ops_log in your Tinybird Pipes to publish your own observability metrics as APIs. Use these APIs to monitor Snowflake sync jobs in your external observability tools.
Related: Build fast charts faster with the Tinybird Grafana plugin
Start building real-time analytics with Snowflake
Ready to get started? Check out the Snowflake Connector docs, or watch the screencast:
If you’re new to Tinybird, you can sign up for free here. The Tinybird Build Plan is free forever, with no time restrictions, no credit card required, and generous limits. Also, feel free to join the Tinybird Community on Slack and ask us any questions or request any additional features.
If you’d like to dig deeper into the Snowflake Connector and its integration with Tinybird, you can also watch our Live Coding Session, where we spent an hour building a real-time analytics demo using the Snowflake Connector and Tinybird.