I’m building TheirStack.com, a market intelligence product for B2B SaaS companies. Among other use cases, it helps our customers find the companies most likely to buy their products. TheirStack identifies the technologies other companies mention in their job posts and delivers that data as buyer intent signals. To do so, we look for thousands of technologies across millions of jobs from hundreds of thousands of companies.
Looking for thousands of text patterns across millions of documents is not trivial. As our data grew, I had to redo our text search scripts multiple times because what worked with small data became too slow when our data got bigger.
How do we do it?
multiMatchAllIndices is all you need. I could end this post here.
But I’ll tell you the story of how we got there. How we started doing text search on Postgres until we couldn’t anymore. What I tried, what worked and what didn’t. And we do it now with ClickHouse (via Tinybird) with data 10 or 100x larger than what Postgres can handle.
Ready? Keep reading.
First we tried to do it in Postgres
PostgreSQL is our main database, where we store data about the jobs we scrape, the companies they’re from, the technologies we track and more. So at first, it felt natural to write some SQL scripts to parse the jobs directly on Postgres, as they were already there.
Attempt #1: Full-Text Search in PostgreSQL
Postgres has full-text search capabilities that would work great to process natural language. This post describes in good detail how it works and how to set it up. Unfortunately, it didn’t fit our use case that well. Some of the reasons are also described in this post from Gitlab about text search on Postgres. To name a few:
1. It’s case-insensitive.
In many cases, we want to make case-sensitive searches. A case-insensitive search is OK if ‘react’ and ‘React’ have the same meaning for you. But for our use case, they don’t, and case-insensitive searches would yield many false positives, which for us have a much higher cost than false negatives.
2. It tokenizes full words and it discards most characters that aren’t letters or numbers.
Look at these two examples:
In our case, those "+" characters in "c++" have meaning and shouldn’t be discarded (which might be ok for most other use cases to make searches on natural text).
In a case like this, where we'd want to differentiate the use of "Go" as a proper noun following a comma and a space, the tokenizer discards that comma (and would discard almost all other special characters). This doesn't work for us.
3. The managed Postgres I use doesn’t support custom dictionaries
Lastly, to customize full-text search you could add your own dictionaries to try to address some of these problems. But Heroku Postgres (what I was using at the time, and what I’m still using), I couldn’t use custom dictionaries, so I didn’t bother trying to make this work anymore.
The official docs are a great place if you want to learn more about this Postgres feature.
Attempt #2: Regex matching in PostgreSQL
Fortunately, Postgres also lets you do pattern matching using regular expressions. So we created one pattern for each technology, and a query like this would return the IDs of the jobs that would match each pattern and were scraped in the current or previous day:
We would run one query like this for every technology we were tracking at the time, every day. We track ~5k technologies, so this is about 5k queries per day.
Then we would save all the combinations of (job_id, technology_id) in an association table that would be updated every day N times, once per technology searched.
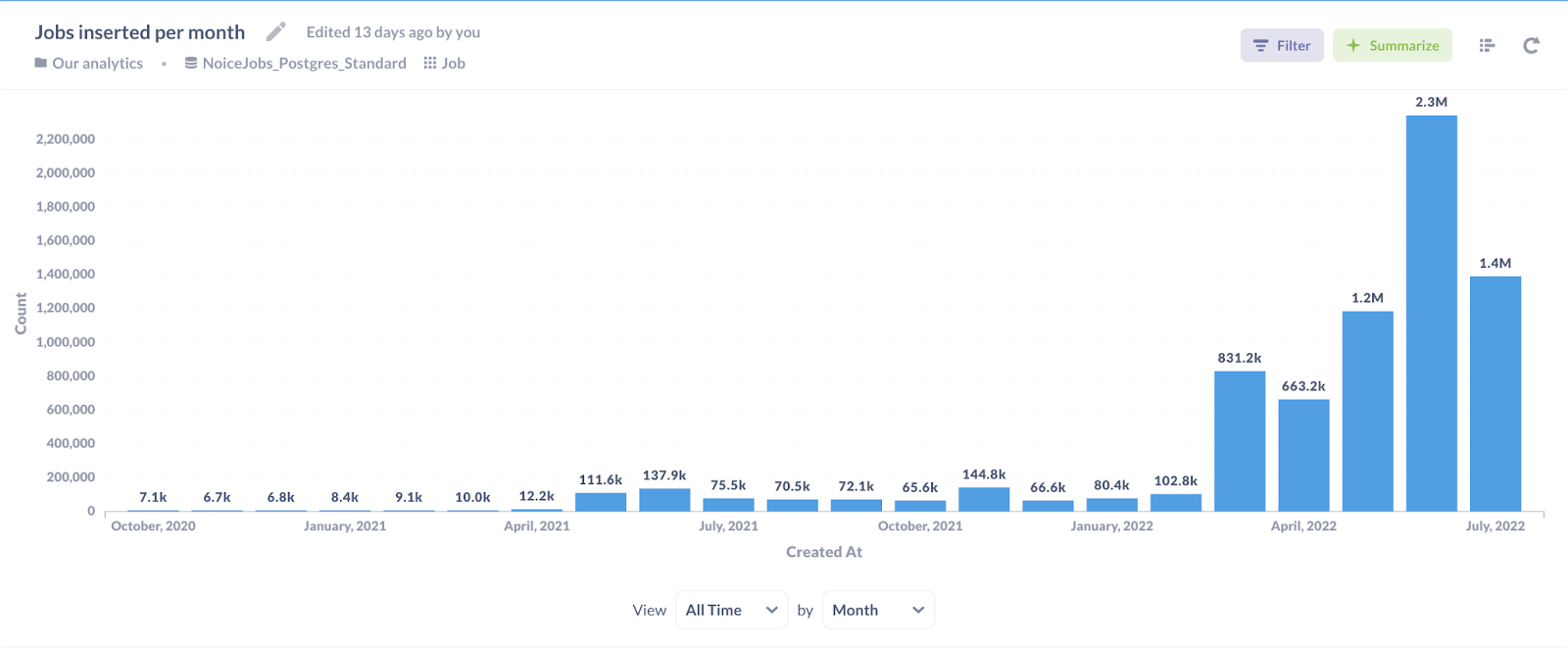
As you see in the previous graph, we were scraping very few jobs in the first months. We didn’t even need an index to run this process in a reasonable time until we had ~50k jobs.
Then, in May 2021 the number of jobs scraped per month grew by 10x, and I had to go back to the drawing board as the previous process got too slow.
Attempt #3: Making it faster with trigram indices
A trigram is a sequence of all the possible 3-character contiguous substrings that can be extracted from a string, and indices on them can make text search queries much faster. You can see what trigrams Postgres produces with the following query
To use trigrams on Postgres, you need to enable the pg_trgm extension running CREATE EXTENSION pg_trgm;.
If you create a GIN or GiST index on the trigram of a column, queries containing LIKE, ILIKE and regex queries on it will be much faster. GIN indices are slower to create but yield faster queries, so I went for that. To create it, you’d run this query:
This sped up text queries by ~10x and was great at the beginning… until it wasn’t.
The description column was quite large, and the trigram index on it was also pretty big - it was taking the same disk space as the column that was being indexed. If we were indexing a column of short text (job titles instead of job descriptions, for example), this approach would still be working today. But that wasn’t the case.
Data kept growing and, when there were ~1M jobs in the database, queries became too slow again, taking seconds to tens of seconds each. And remember, we were running one query per technology and tracking thousands of technologies. Also, running these queries would put too much load on the Postgres database I was using, in addition to it not being fast enough anymore.
So I started looking for alternatives.
Then we moved to Tinybird
I knew there were text-specific search solutions out there such as ElasticSearch or Algolia. But I had worked at Tinybird before, was more familiar with it, and I knew it operated on ClickHouse. I also knew that ClickHouse could do pattern matching on text. And I thought that storing data in a columnar format as ClickHouse does would likely make those operations much faster than on Postgres.
So I did a quick test, loading ~1M rows from my jobs table on Postgres on Tinybird, and was happily surprised with the results.
I wrote a script to ingest the latest jobs data from Postgres to Tinybird every 10 minutes, similar to what’s described here.
Then I wrote a Tinybird Pipe that does the same pattern matching thas was being done on Postgres. There’s no ~* or ~ operator in ClickHouse, but the match function does the same thing. A ClickHouse equivalent query to the Postgres one shown before would look like this, using Tinybird dynamic parameters.
Note that match is case-sensitive, so if you want to make case-insensitive queries you need to make the pattern start with (?i).
This was indeed much faster, and for a few months it worked just fine. But there was a problem.
Again, we track about 5,000 technologies and we need to make one query per technology, reading the same data. The jobs datasource is sorted by date_posted so that queries only read the data they need. But even if the data for the last day only takes 100MB, 100MB * 10,000 = 1TB read per day… not a number I feel comfortable with.
So I started to look for ways to do the same, but more efficiently.
A failed idea: ngrambf_v1 indices for full-text search on ClickHouse
The first thing I looked for was whether there was something like PostgreSQL’s trigram indexes on ClickHouse. There are: ngrambf_v1 indexes. You can see all the available indexes on the official docs, and an extended explanation on how indices work on ClickHouse in this post from Altinity.
The internals of ngrambf_v1 indices on ClickHouse are similar to trigram indexes in Postgres.
First, ngrams of the size we choose (3 in this case) are extracted from the column to be indexed. The ngrams function produces substrings of N characters.
Then the index stores in which granules each substring appears.
There are several reasons this didn’t work for us. The first one is that, unlike in Postgres, ngram indices can’t optimize regex matching functions in ClickHouse. Only functions that search for substrings in strings can be optimized by ngrambf_v1 indices in ClickHouse. These are functions like LIKE, ILIKE and multiSearchAny, but any functions involving match (that use regex patterns) won’t be faster by using an index like this (source: this table in the docs).
Another valid reason is that Tinybird doesn’t let you set up indices yet. It lets you set up the sorting key of a Data Source, which is fine for most cases as it’s one of the most important settings to make your queries fast. If you’re going to filter or group by column_a in most of your queries, that should be the first element of the sorting_key setting of your Data Source (read more on making queries fast in this guide and how to pick good sorting and partition keys here).
Last, even if I could get by matching substrings, and I could set up ngrambf_v1 indices on Tinybird, I’m still not sure text indices on such large columns as job_description would be useful, while keeping ClickHouse performant. This is because indices work differently in ClickHouse compared to in Postgres, for good reasons.
In Postgres, index entries will point to specific rows in your tables. In ClickHouse, indices will point to N granules (1 in the example below, the value after INDEX… GRANULARITY), where a granule is a set of M rows (the value after SETTINGS index_granularity = ).
Imagine our table definition is like this:
index_granularity defines the number of rows per granule. It’s 100 in this case, but for analytics use cases it makes sense to put a much larger value there. The default value is 8192. Here rows will be sorted by date_posted and the primary index will only contain 1 value for every 100 rows. This is great for analytical queries, as filters and aggregations based on date_posted will be very fast. The smaller the granule size is, the bigger the primary index will become and these queries will run slow.
Check out this section of the docs to understand how Primary indices work on ClickHouse and this StackOverflow answer to learn more about table granularity and index granularity work. These slides are also full of good performance tips about indices, column encodings and more.
Here comes the problem.
An index will be useful if it can discard lots of rows (or granules, in our case). The column indexed (containing job descriptions) will be quite large, and a granule will contain many rows. So most granules will contain most ngrams, and the index won’t be able to discard many granules unless we set the granule size to very few rows (10 or less). But, as we said before, a very selective index (with a low number of rows per granule) will degrade the performance of other queries. Also, it must fit in memory. Everything is a trade-off!
To sum this part up: ngrambf_v1 filters can be good to speed up text searches on ClickHouse if:
- The values of the indexed column are rather small (the
job_titlecolumn would be a good candidate for this, for example) - You can use them (you can’t yet on Tinybird)
- And you don’t need to do pattern matching and substring matching is enough for you
Extra: tokenbf_v1 indices for full-text search
ClickHouse has another type of index that stores tokens that could also be useful if you want to process natural language. You can see how ClickHouse extract tokens with the tokens function:
Then, to check if a token exists in a string or column, we’d use the function hasToken:
As you see, it’s case-sensitive:
To add a tokenbf_v1 index to the jobs table, we’d run something like ALTER TABLE .table_name ADD INDEX ix_job_token_description description TYPE ngrambf_v1(1024, 5, 0) GRANULARITY 1
But this approach wouldn’t work for us either because it also removes special characters and multi-word patterns couldn’t be parsed this way.
Fortunately, a few weeks later I found something that let me reduce the data I was reading by 10,000x and parse ALL technologies in just a few seconds with a single call…
The Final Solution: multiMatchAllIndices on Tinybird
A few weeks after that I was taking a look at the string search section of the ClickHouse docs and the short description of the multiMatchAllIndices function caught my attention:
“The same as multiMatchAny, but returns the array of all indices that match the haystack in any order.”
Better seen with an example:
This is how you’d run the same query over a full column, instead of over a dummy hardcoded string.
These are some of the steps we followed to hit our use case to a T with the multiMatchAllIndices function:
Make case-insensitive searches
Adding (?i) at the beginning of every pattern makes it case-insensitive, like we did before:
Add an edit distance for fuzzy string matching
ClickHouse also lets you do fuzzy matching, where you can pass an edit distance to get exact matches and also similar, non-exact ones:
Get the indices and also the matching words
Want to get also the exact words from the text column that match the array of patterns passed? I got you covered.
Get the whole line where the matches were found.
To have more context on whether a company is actually using a technology or it’s just part of a big “wishlist”, it’s useful to see the sentence where they mention it. This is how to see it all at a glance.
Parse lots of patterns at once via parameter
This is coming to an end, I promise. But one last thing: You probably don’t want to type the array of patterns into your queries. With Tinybird, you could pass them via a dynamic parameter doing something like this:
With this approach you’ll be able to parse ~200 patterns or so with Tinybird at once, but not more because if the array of patterns you pass it too long, you’ll hit the 8kb per SQL length limit.
Read the patterns from disk
But what if you want to parse 2,000 patterns at once? Or 20,000? Or… 200,000? You could store them in another table. I loaded some of the most common technologies TheirStack tracks (you can see the full list here) into a DataSource, so that we can see a live query of how this would work.
Finally, to parse all the technologies at once, you’d read them from this Data Source with the groupArray function as an array, and this query would tell you the indices of the patterns of the array that match each job:
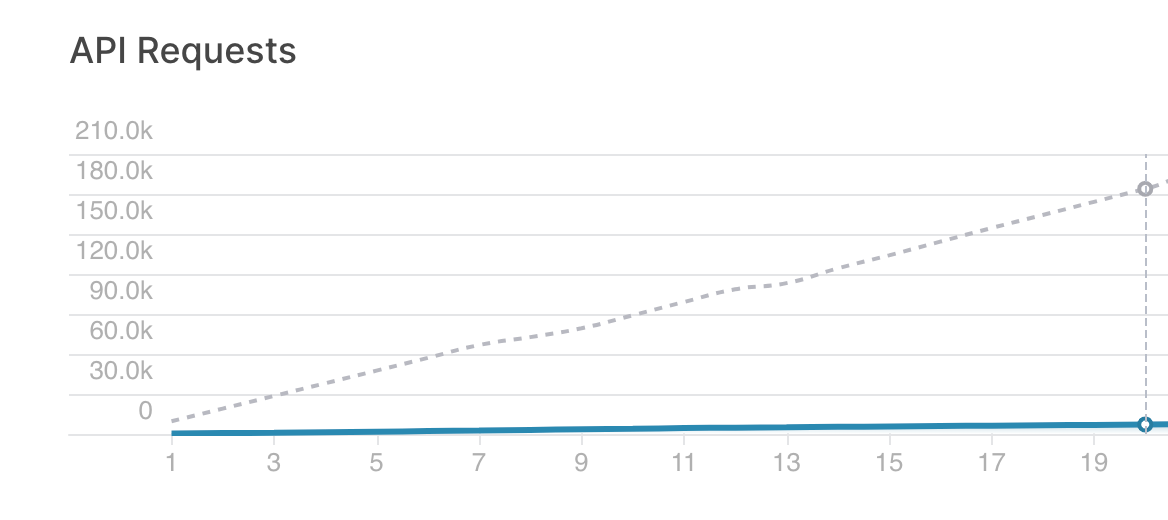
With this approach we were able to collapse 5,000 queries into just one, reducing significantly the amount of data we read and the queries we make, as you can see in this chart (where the blue line is the number of queries made this month and the dotted line is the number of queries made in the previous approach)
I could keep talking about extracting data from jobs for hours, but I think it’s time to call it a day. If you want to find the tech stack of potential customers, check out TheirStack’s website, and if you wanna talk more about this, you can find me on Twitter or on Tinybird’s Slack community.
Thanks for reading!









